Von Googles Webmastertools wurde ich eben darauf hingewiesen, dass eine meiner MODx Revo Sites offenbar URLs für Spammer redirected. Sie Website verwies also auf dubiose Shops mit Medikamenten und anderem Gedöns.
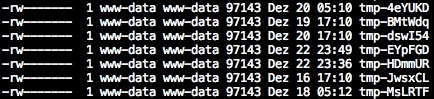
Nach einer ausgedehnten Analyse habe ich dann zunächst in core/cache/ mehrere tmp-* Dateien gefunden, die offenbar immer dann angelegt wurden, wenn eine dieser URLs aufgerufen worden ist.
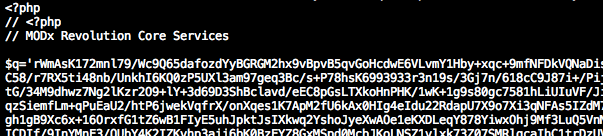
 Die Datei selbst enthielt etwas PHP Code, der sich gegenüber Google und anderen Suchmaschinen unsichtbar machte, in dem der Code nur ausgeführt wurde, wenn der Request nicht von bestimmten IPs oder Agents kam. Im Web habe ich darüber etwas unter dem Begriff "Google Conditional Hack" gefunden, z.B. hier. Scheinbar existiert dieser Hack für diverse CMS Systeme, nicht nur für MODx Revo. In meinem speziellen Fall scheint der Angriff zumindest auf MODx angepasst worden zu sein, denn er gibt sich als Core Komponente aus, damit Benutzer ihn nicht finden oder sich nicht trauen ihn zu löschen:
Die Datei selbst enthielt etwas PHP Code, der sich gegenüber Google und anderen Suchmaschinen unsichtbar machte, in dem der Code nur ausgeführt wurde, wenn der Request nicht von bestimmten IPs oder Agents kam. Im Web habe ich darüber etwas unter dem Begriff "Google Conditional Hack" gefunden, z.B. hier. Scheinbar existiert dieser Hack für diverse CMS Systeme, nicht nur für MODx Revo. In meinem speziellen Fall scheint der Angriff zumindest auf MODx angepasst worden zu sein, denn er gibt sich als Core Komponente aus, damit Benutzer ihn nicht finden oder sich nicht trauen ihn zu löschen:
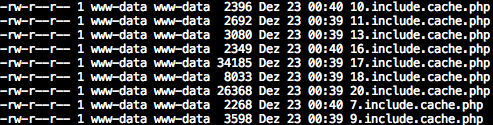
Aber woher kamen diese Dateien? Ein auffälliger String im Code ("tmhapbzcerff") war wie gemacht als Suchmuster. Also bemühte ich grep um das Muster vielleicht auch noch in anderen Dateien zu finden. Tatsächlich wurde ich fündig: Auch in core/cache/includes/elements/modplugin/20.include.cache.php existierte dieser String.
 Cache und tmp Dateien löschen führte zwar dazu, dass die Dateien weg waren, aber kurze Zeit später tauchten sie wieder auf. Also musste es noch einen tiefer liegenden Auslöser dafür geben.
Cache und tmp Dateien löschen führte zwar dazu, dass die Dateien weg waren, aber kurze Zeit später tauchten sie wieder auf. Also musste es noch einen tiefer liegenden Auslöser dafür geben.
Das core/cache/includes/elements/modplugin/ Verzeichnis wird als Cache erstellt, wenn MODx Plugins ausgeführt werden. Der erste Zahlenwert des Dateinamens, so vermutete ich, könnte die ID eines Datensatzes sein.
 Ein Blick in die Datenbank von MODx zeigte eine Tabelle namens modx_site_plugins. Das könnte passen.
Ein Blick in die Datenbank von MODx zeigte eine Tabelle namens modx_site_plugins. Das könnte passen.
In dieser Tabelle gab es einen Datensatz mit der ID 20 und dem Namen "Search Highlighter". In den Details sah man dann auch den Schadcode, zwar encrypted, aber durchaus identifizierbar. Nach dem entfernen dieses Datensatzes und dem erneuten Löschen des Cache und der tmp Dateien ist der Schadcode nun verschwunden.
Wie der Code jedoch in die Datenbank kam, konnte ich noch nicht herausfinden. Da ich die aktuellste Version von MODx Revo einsetze (2.3.2-pl) könnte es natürlich darin eine Sicherheitslücke geben, eine Suche ergab dazu jedoch keine Treffer. Theoretisch könnte der Schadcode schon sehr lange drin gewesen sein und entweder nicht aktiv oder unbemerkt. Möglich wäre auch eine SQL Injection in der Vergangenheit in einer älteren MODx Version.
Update am 23.12.2014: Ich hatte noch nicht alles erwischt und entfernt. Nach einigen Stunden waren dann wieder die gleichen Dateien vorhanden. Durch einen Hinweis von @JayGilmore kam ich dann auf die Seite http://forums.modx.com/thread/89564/warning-hacking-attack-on-revo-2-2-4-using-core-services-plugin und sah dort, dass ich ein Plugin noch nicht entfernt hatte. Das war mir gestern auch schon aufgefallen, aber ich rechnete es nicht dem Hack zu. Das habe ich jetzt auch noch entfernt - mal sehen ob das nun alles war.
Es handelt sich wohl um einen Hack, der vor MODx 2.2.14 bereits durchgeführt, aber bis vor kurzem nicht ausgenutzt wurde.

 .
.